- 분류 전체보기 (410)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- Airflow
- JPA
- Docker Compose
- Selenium
- spring cloud
- WebLogic
- argo cd
- spring boot
- MySQL
- grafana
- coalesce
- docker compose mysql
- KAFKA
- Netty
- weblogic 10
- QueryDSL
- netflix oss
- docker
- ChannelPipeline
- vue.js
- docker-compose
- Hibernate
- cassandra
- mybatis
- redis
- Spring Open Feign
- spring boot redis
- Redis Sentinel
- RabbitMQ
- jmeter
- Today
- Total
IT.FARMER
spark linux install (Master / Worker) 본문
2020/04/03 - [BigData/Spark] - spark linux install (Master / Worker)
2020/04/06 - [BigData/Spark] - spark sql
2020/04/06 - [BigData/Spark] - Spark 모니터링
2020/04/06 - [BigData/Spark] - Spark Dataset
2020/04/06 - [BigData/Spark] - Spark Dataset 데이터 조회 예제
2020/04/06 - [BigData/Spark] - Dataset DataFrame Convert
2020/04/06 - [BigData/Spark] - Spark submit
메소스, 하둡얀 등 여러 에코시스템이 있지만, 순수 스파크만 이용할경우 spark - standalone 방식으로 사용한다.
다운로드 받은 파일을 Master ,Worker1 폴더를 생성하여 압축해제후 두개의 폴더로 복사
파일 다운로드시 빌트인된 하둡을 선택하여 다운 받는다.
tar -xbzf spark-3.0.0-preview2-bin-hadoop2.7.tgz
cp spark-3.0.0-preview2-bin-hadoop2.7 master
cp spark-3.0.0-preview2-bin-hadoop2.7 worker1
압축을 해제 한뒤에 Master 폴더 worker1 형태로 폴더를 만들어주고 복사한다.
Master 환경설정 (Master Node 에서만 수행)
1. Configuration
# 환경설정 파일 복사
cd ./conf cp spark-env.sh.template spark-env.sh
cp spark-defaults.conf.template spark-defaults.conf
# Cluster 구성시 작업 필요 (단일 서버시 하지 설정 할 필요 없음)
# 노드로 사용할 슬레이브 서버를 적어준다.
# worker host -> slave 의 IP 혹은 host 명. (Cluster 구성에 필요)
cd ./conf cp slaves.template slaves
vim slaves
...
192.168.0.2
192.168.0.3
192.168.0.4
...
1.1 spark-env Host 설정
vim spark-env.sh
# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname export SPARK_MASTER_HOST=10.184.70.55
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
1.2 설정 및 옵션 설정
# 기본 설정 파일 변경
vim spark-defaults.conf
...
spark.master spark://192.168.0.1:7077 # master 정보
spark.eventLog.enabled true #spark history web ui 사용시 필요함.
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" ...
1.3 master 실행
./sbin/start-master.sh
#log 확인
tail -f master/spark-2.4.4-bin-hadoop2.7/logs/spark-mezzo-org.apache.spark.deploy.master.Master-1-AnSangKil.out
노드로 사용할 슬레이브 서버를 설정 했다면. 하나의 명령어로 모든 슬레이브를 한번에실행 시킬수 있다
. ./sbin/start-all.sh ssh key 설정을 하지 않았다면 디렉토리 접근 오류가 발생된다.
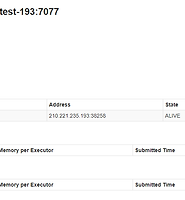
master 를 실행한후 {MASTER_IP}:8080 으로 접속하여 웹UI를 확인 할 수 있다. worker는 아직 실행 하지 않았음으로 목록에서 볼수 없다.
worker 실행
worker 실행시 복사한 폴더에서 실행 하며, {spark-url} 은 master - web ui (8080 port )에서 확인 할수 있고 spark://..... 로 시작된다. SLAVE 에서 사용할 환경설정을 해준후 sbin/start-slave.sh 명령어로 worker를 실행시켜 준다.
# 기본 명령어
./sbin/start-slave.sh {spark-master-url} {option}
./sbin/start-slave.sh spark://10.184.70.55:7077
#추가 옵션으로 메모리와 코어 할당
./sbin/start-slave.sh spark://10.184.70.55:7077 -m 1024M -c 1
./sbin/start-slave.sh spark://210.221.235.193:7077 -m 1024M -c 1
./sbin/start-slave.sh spark://210.221.235.209:7077
#option 정보
-m 메모리
-c 코어 수
# 아래 URL 참고
Spark Configration Cluster Manually
spark-env.sh option
Shell(Client) 접속 및 Spark 테스트
./spark-shell --master spark://hostname:7077
# ...

'BigData > Spark' 카테고리의 다른 글
| Spark Dataset (0) | 2020.04.06 |
|---|---|
| Spark 모니터링 (0) | 2020.04.06 |
| spark sql (0) | 2020.04.06 |
| Spark ML pipeline (0) | 2017.06.16 |
| Spark 설치 및 실습 (0) | 2017.06.16 |